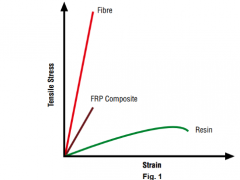
随着科技的发展,纤维增强聚合物复合材料作为一种新型的高性能材料,在航空航天、汽车、船舶等领域得到了广泛应用。然而,在高温环境下,这种材料的拉伸强度会发生变化,从而影响其使用性能。因此,准确预测纤维增强聚合物复合材料在高温下的拉伸强度对于工程设计和材料应用具有重要意义。近年来,基于机器学习的预测模型在材料科学领域得到了广泛关注,本文旨在构建一个基于机器学习的纤维增强聚合物复合材料高温拉伸强度预测模型。
首先,我们需要收集大量的纤维增强聚合物复合材料高温拉伸强度的实验数据。这些数据应包括不同材料类型、不同纤维含量、不同温度条件下的拉伸强度值。在收集数据时,需要注意数据的准确性和完整性,以确保预测模型的可靠性。

接下来,我们需要对收集到的数据进行预处理。这包括数据清洗、数据归一化、特征选择等步骤。数据清洗的目的是去除数据中的噪声和异常值,以提高预测模型的准确性。数据归一化则是将数据转换到同一范围内,以便模型能够更好地处理不同特征之间的量纲差异。特征选择则是从原始特征中选择出对预测结果影响较大的特征,以提高模型的泛化能力。
在数据预处理完成后,我们可以选择合适的机器学习算法来构建预测模型。常见的机器学习算法包括线性回归、支持向量机、随机森林、神经网络等。在选择算法时,需要考虑算法的性能、模型的复杂度和计算成本等因素。针对纤维增强聚合物复合材料高温拉伸强度预测问题,我们可以尝试使用神经网络算法,因为该算法具有较强的非线性拟合能力和自适应性。
在确定了机器学习算法后,我们需要使用训练数据对模型进行训练。训练过程中,需要选择合适的优化算法和损失函数,并调整模型的超参数以达到最优的预测性能。同时,我们还需要对模型进行验证和测试,以评估其泛化能力和预测精度。在评估模型时,可以采用交叉验证、均方误差、决定系数等指标来衡量模型的性能。
除了模型的训练和评估外,我们还需要对模型进行解释和可视化。这有助于我们理解模型的预测结果和特征之间的关系,从而更好地指导材料设计和应用。常见的模型解释和可视化方法包括特征重要性分析、部分依赖图、混淆矩阵等。
最后,我们需要将构建好的预测模型应用于实际工程中。在实际应用中,需要注意模型的适用范围和限制条件,以避免出现预测失误或过度泛化等问题。同时,我们还需要对模型进行定期的更新和维护,以适应材料性能的变化和工程需求的发展。
综上所述,基于机器学习的纤维增强聚合物复合材料高温拉伸强度预测模型是一种有效的工程设计和材料应用工具。通过收集实验数据、进行数据预处理、选择合适的机器学习算法、训练模型、评估模型性能、解释和可视化模型以及实际应用等步骤,我们可以构建出一个准确、可靠的预测模型,为纤维增强聚合物复合材料在高温环境下的应用提供有力支持。